Parslets
Overview
After populating a named buffer with data from an external source such as an HTTP request or a file, it is often necessary to extract fields from it for uses such as creating subsequent HTTP requests or rendering output csv files.
This is accomplished using parslets. There are two types of parslet, static and dynamic. In both cases, when a parslet is used in a script it is expanded such that it is replaced with the value it is referencing, just like a variable is.
- Static parslets refer to a fixed location in XML or JSON data
- Dynamic parslets are used in conjunction with foreach loops to retrieve values when iterating over arrays in XML or JSON data
Parslets can be used to query JSON or XML data. Although JSON is used for illustrative purposes, some additional notes specific to XML can be found further down in this article.
A quick JSON primer
Consider the example JSON shown below:
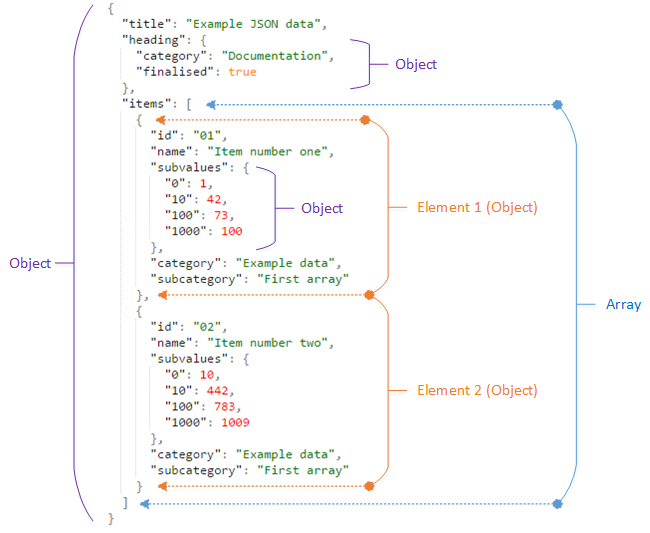
The object containing all the data (known as the root node) contains the following children:
| Child | Type |
|---|---|
| title | string |
| heading | object |
| items | array |
Objects and arrays can be nested to any depth in JSON. The children of nested objects and arays are not considered as children of the object containing those objects and arrays, i.e. the children of the heading object are not considered as children of the root object.
Every individual 'thing' in JSON data, regardless of its type is termed a node.
Although different system return JSON in different forms, the JSON standard dictates that the basic principles apply universally to all of them. Thus, any possible valid JSON may contain arrays, objects, strings, boolean values (true or false values), numbers and null children.
It is often the case that the number of elements in arrays is not known in advance, therefore a means of iterating over all the elements in an array is required to extract arbitrary data from JSON. This principle also applies to objects, in that an object may contain any number of children of any valid type. Valid types are:
| Type | Description |
|---|---|
object | A node encompassing zero or more child nodes (termed children) of any type |
array | A list of children, which may be of any type (but all children in any given array must be of the same type) |
string | Textual data |
number | Numeric data, may be integer or floating point |
boolean | A true or false value |
null | A null value |
Some systems return JSON in a fixed and predictable format, whereas others may return objects and arrays of varying length and content. The documentation for any given API should indicate which fields are always going to be present and which may or may not be so.
Parslets are the means by which USE locates and extracts fields of interest in any valid JSON data, regardless of the structure. For full details of the JSON data format, please refer to http://json.org
Static parslets
Static parslets act like variables in that the parslet itself is expanded such that the extracted data replaces it. Static parslets extract a single field from the data and require that the location of that field is known in advance.
In the example JSON above, let us assume that the data is held in a named buffer called example and that the title and heading children are guaranteed to be present. Further, the heading object always has the children category and finalised. Note that for all of these guaranteed fields, the value associated with them is indeterminate.
The values associated with these fields can be extracted using a static parslet which is specified using the following syntax:
$JSON{buffer_name}.[node_path]
Static parslets always specify a named buffer in curly braces immediately after the $JSON prefix
The buffer_name is the name of the buffer containing the JSON data, which must have previously been populated using the buffer statement.
The node_path describes the location and name of the node containing the value we wish to extract. Starting at the root node, the name of each node leading to the required value is specified in square brackets. Each set of square brackets is separated by a dot.
The nodepaths for the fixed nodes described above are therefore as follows:
| Nodepath | Referenced value |
|---|---|
.[title] | Example JSON data |
.[heading].[category] | Documentation |
.[heading].[finalised] | true |
Putting all the above together, the parslet for locating the category in the heading is therefore:
$JSON{example}.[heading].[category]
When this parslet is used in a USE script, the value associated with the parslet is extracted and the parslet is replaced with this extracted value. For example:
print $JSON{example}.[heading].[category]
will result in the word Documentation being output by the statement, and:
var category = $JSON{example}.[heading].[category]
will create a variable called category with a value of Documentation.
Currently, a parslet must be followed by whitespace in order to be correctly expanded. If you want to embed the value into a longer string, create a variable from a parslet and use that instead:
var category = $JSON{example}.[heading].[category]
var filename = JSON_${category}_${dataDate}
When using JSON parslets that reference values that may contain whitespace it is sometimes necessary to enclose them in double quotes to prevent the extracted value being treated as multiple words by the script
Anonymous JSON arrays
It may be required to extract values from a JSON array which contains values that do not have names as shown below:
{
"data": {
"result": [
{
"account": {
"name": "account_one"
},
"metrics": [
[
34567,
"partner"
],
[
98765,
"reseller"
]
]
},
{
"account": {
"name": "account_two"
},
"metrics": [
[
24680,
"internal"
],
[
13579,
"partner"
]
]
}
]
}
}
Extraction of values that do not have names can be accomplished via the use of nested foreach loops in conjunction with an empty nodepath ([]) as follows:
buffer json_data = FILE system/extracted/json.json
csv OUTFILE = system/extracted/result.csv
csv add_headers OUTFILE account related_id type
csv fix_headers OUTFILE
foreach $JSON{json_data}.[data].[result] as this_result {
# Extract the account name from each element in the 'result' array
var account_name = $JSON(this_result).[account].[name]
print Processing namespace: ${account_name}
# Iterate over the metrics array within the result element
foreach $JSON(this_result).[metrics] as this_metric {
# As the metrics array contains anonymous arrays we need to iterate
# further over each element. Note the use of an empty notepath.
foreach $JSON(this_metric).[] as this_sub_metric {
if (${this_sub_metric.COUNT} == 1) {
# Assign the value on the first loop iteration to 'related_id'
var related_id = $JSON(this_sub_metric).[]
}
if (${this_sub_metric.COUNT} == 2) {
# Assign the value on the second loop iteration to 'type'
var type = $JSON(this_sub_metric).[]
}
}
csv write_fields OUTFILE ${account_name} ${related_id} ${type}
}
}
csv close OUTFILE
The result of executing the above against the sample data is:
"account","related_id","type"
"account_one","34567","partner"
"account_one","98765","reseller"
"account_two","24680","internal"
"account_two","13579","partner"
If the anonymous arrays have a known fixed length then it is also possible to simply stream the values out to the CSV without bothering to assign them to variables. Thus assuming that the elements in the metrics array always had two values, the following would also work:
buffer json_data = FILE system/extracted/json.json
csv OUTFILE = system/extracted/result.csv
csv add_headers OUTFILE account related_id type
csv fix_headers OUTFILE
foreach $JSON{json_data}.[data].[result] as this_result {
# Extract the account name from each element in the 'result' array
var account_name = $JSON(this_result).[account].[name]
print Processing namespace: ${account_name}
# Iterate over the metrics array within the result element
foreach $JSON(this_result).[metrics] as this_metric {
# As the metrics array contains anonymous arrays we need to iterate
# further over each element. Note the use of an empty notepath.
csv write_field OUTFILE ${account_name}
foreach $JSON(this_metric).[] as this_sub_metric {
csv write_field OUTFILE $JSON(this_sub_metric).[]
}
}
}
csv close OUTFILE
Which method is used will depend on the nature of the input data. Note that the special variable ${loopname.COUNT} (where loopname is the label of the enclosing foreach loop) is useful in many contexts for applying selective processing to each element in an array or object as it will be automatically incremented every time the loop iterates. See foreach for more information.
Dynamic parslets
Dynamic parslets are used in to extract data from locations in the data that are not known in advance, such as when an array of unknown length is traversed in order to retrieve a value from each element in the array.
A dynamic parslet must be used in conjunction with a foreach loop and takes the following form:
$JSON(loopName).[node_path]
Note the following differences between a static parslet and a dynamic parslet:
- A dynamic parslet does not reference a named buffer directly, rather it references the name of a foreach loop
- Parentheses are used to surround the name of the foreach loop (as opposed to curly braces)
- The nodepath following a dynamic parslet is relative to the target of the foreach loop
The following script fragment will render the elements in the items array (in the example JSON above) to disk as a CSV file.
# For illustrative purposes assume that the JSON
# is contained in a named buffer called 'myJSON'
# Create an export file
csv "items" = "system/extracted/items.csv"
csv add_headers id name category subcategory
csv add_headers subvalue1 subvalue2 subvalue3 subvalue4
csv fixheaders "items"
foreach $JSON{myJSON}.[items] as this_item
{
# Define the fields to export to match the headers
csv write_field items $JSON(this_item).[id]
csv write_field items $JSON(this_item).[name]
csv write_field items $JSON(this_item).[category]
csv write_field items $JSON(this_item).[subcategory]
# For every child of the 'subvalues' array in the current item
foreach $JSON(this_item).[subvalues] as this_subvalue
{
csv write_field items $JSON(this_item).[0]
csv write_field items $JSON(this_item).[10]
csv write_field items $JSON(this_item).[100]
csv write_field items $JSON(this_item).[1000]
}
}
csv close "items"
In the example above, the first foreach loop iterates over the elements in the 'items' array, and each of the dynamic parslets extract values from the current element in that loop. The dynamic parslets use the current element, this_item as the root for their node paths.
If a parslet references a non-existent location in the XML or JSON data then it will resolve to the value EXIVITY_NOT_FOUND
XML parslets
XML parslets work in exactly the same way that JSON parslets do, apart from the following minor differences:
- XML parslets are prefixed
$XML - When extracting data from XML, the
foreachstatement only supports iterating over XML arrays (whereas JSON supports iterating over objects and arrays) - An XML parslet may access an XML attribute
To access an XML attribute, the node_path should end with [@atrribute_name] where attribute_name is the name of the attribute to extract. For example given the following data in a buffer called xmlbuf:
<note>
<to>Tove</to>
<from>
<name comment="test_attribute">Jani</name>
</from>
<test_array>
<test_child>
<name attr="test">Child 1</name>
<age>01</age>
</test_child>
<test_child>
<name attr="two">Child 2</name>
<age>02</age>
</test_child>
<test_child>
<name attr="trois">Child 3</name>
<age>03</age>
</test_child>
<test_child>
<name attr="quad">Child 4</name>
<age>04</age>
</test_child>
</test_array>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
The following script:
foreach $XML{xmlbuf}.[test_array] as this_child {
print Child name ${this_child.COUNT} is $XML(this_child).[name] and age is $XML(this_child).[age] - attribute $XML(this_child).[name].[@attr]
}
will produce the following output:
Child name 1 is Child 1 and age is 01 - attribute test
Child name 2 is Child 2 and age is 02 - attribute two
Child name 3 is Child 3 and age is 03 - attribute trois
Child name 4 is Child 4 and age is 04 - attribute quad