Establishing Sustainable Right-Sizing Practices for Cloud Resources
A FinOps-aligned, cloud-agnostic framework for balancing financial efficiency and operational resilience
Authors: Ismael Rivera Álvarez, Bernd Kaponig, Michiel de Vos, Tim Rab Date: January 2026
Summary
This paper presents a FinOps-aligned, cloud-agnostic framework for establishing a sustainable practice for right-sizing cloud resources.
It is intended to help organizations:
- Systematically identify and remove wasteful over-provisioning without compromising reliability.
- Move from ad-hoc tuning to a repeatable, measurable capability embedded in day-to-day engineering work.
- Integrate right-sizing with FinOps maturity, personas, and governance, rather than treating it as a one-off cost-cutting exercise.
- Align right-sizing activities across compute, storage, databases, containers/Kubernetes, and network in multi-cloud environments.
After reading this paper, a practitioner should be able to:
- Design and run a right-sizing program mapped to Crawl / Walk / Run maturity.
- Identify the highest-value optimization levers across major cloud resource types.
- Define KPIs, guardrails, and workflows that support sustainable optimization instead of one-time cost reductions.
- Connect right-sizing decisions to FinOps capabilities such as Resource Utilization & Efficiency, Cost Allocation, Forecasting, and Workload Management & Automation.
Who Should Read This Paper
This paper is written for:
- FinOps practitioners and teams
Those responsible for cloud cost visibility, optimization, and cross-functional collaboration. - Engineering and platform teams
Developers, SREs, platform engineers, architects, and operations teams who design, run, and scale services. - Product and business owners
Owners of services or portfolios who are accountable for service quality and cost outcomes. - Finance and FP&A
Teams that translate right-sizing and optimization outcomes into budgets, forecasts, and business decisions. - Technology and business leadership
Leaders sponsoring FinOps as a practice who need a structured way to align cost efficiency with strategic priorities.
Prerequisites
Readers will get the most value out of this paper if they have:
- A basic understanding of cloud infrastructure and services (IaaS, PaaS, managed services).
- Familiarity with the FinOps Framework, particularly:
- Resource Utilization & Efficiency
- Cost Allocation & Showback
- Workload Management & Automation
- Forecasting & Budgeting
- Access to at least a minimal set of:
- Cloud usage and cost data
- Monitoring/observability metrics
- Tagging or account structure to map resources to products, teams, or cost centers.
1. Introduction
1.1 Background and Significance
The widespread adoption of cloud computing has fundamentally changed how organizations provision, consume, and pay for infrastructure. Instead of fixed capacity in centralized data centers, teams now work with effectively infinite, elastic capacity available on demand.
While this has unlocked enormous flexibility and speed, it has also introduced new forms of waste, fragmentation, and complexity:
- Over-provisioned instances, clusters, and databases sized for "worst case" scenarios.
- Idle or zombie resources that are no longer needed but continue to incur cost.
- Overly conservative architectures that trade large amounts of cost for small theoretical increases in resilience.
- Underused high-performance storage, networking, and premium features that deliver little incremental value.
How to Think About Right-Sizing
Traditionally, organisations view right-sizing as a reactive "spring cleaning" event. A periodic purge of waste triggered by budget overruns.
In a FinOps context, you should instead think of right-sizing as continuous inventory velocity. Just as a retailer does not want inventory sitting on a shelf gathering dust, a specialised engineering organisation does not want compute capacity sitting idle. Right-sizing is the active discipline of ensuring every unit of infrastructure rented is converting directly into business value. It balances the "Iron Triangle" of Cost, Speed, and Quality.
Right-sizing is the discipline of aligning resource capacity with actual workload needs over time. When systematically applied, it becomes one of the most powerful FinOps levers to:
- Unlock "hidden" capacity and budget without asking for new investment.
- Enhance sustainability by minimising unnecessary infrastructure and energy consumption.
- Create tangible feedback loops between engineering and finance.
1.2 Objectives and Scope
This paper focuses on:
- Establishing sustainable right-sizing practices for:
- Compute (VMs, serverless, managed compute)
- Storage (block, object, file)
- Databases (managed and self-hosted)
- Containers and Kubernetes
- Network components (load balancers, gateways, connectivity)
- Integrating right-sizing with:
- FinOps maturity (Crawl / Walk / Run)
- Key personas and their responsibilities
- KPIs and indicators of success
- Tooling and automation strategies
- Providing practitioner-oriented examples, patterns, and visuals to support implementation.
We focus on cloud-agnostic concepts and practices that can be applied across providers (AWS, Azure, GCP, and others), while acknowledging provider-specific details where useful.
2. Right-Sizing in the Context of FinOps
2.1 FinOps Foundations: Resource Utilisation & Efficiency
The FinOps Framework defines Resource Utilisation & Efficiency as the capability to ensure cloud resources are configured and used optimally to deliver business value.
Core principles relevant to right-sizing include:
- Visibility
Having a consistent, trusted view of what resources exist, what they cost, and how they are used. - Measurement
Translating utilization metrics (CPU, memory, storage, IOPS, network, requests, etc.) into meaningful signals of efficiency or waste. - Optimization
Taking targeted actions to improve the relationship between cost, performance, and risk, not just one of them. - Iteration
Treating right-sizing as an ongoing practice, not a one-time clean-up.
In practice, right-sizing integrates tightly with the Inform → Optimize → Operate FinOps lifecycle:
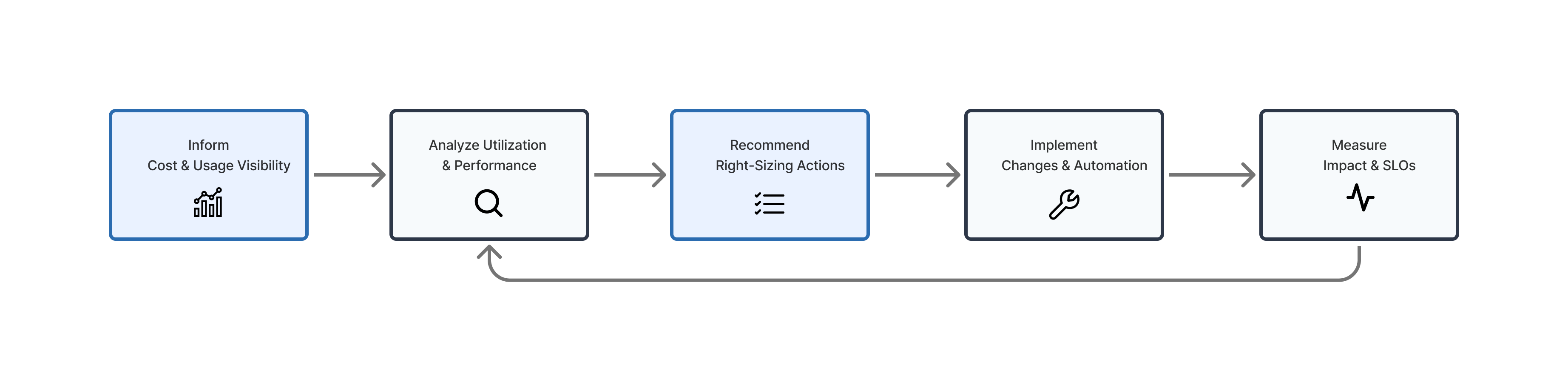
2.2 The Evolution of Right-Sizing
Most organizations follow a similar evolutionary path:
Ad-hoc clean-ups
Someone notices an expensive instance or cluster and manually resizes or shuts it down.
Periodic, manual reviews
Teams begin to analyze dashboards monthly or quarterly and apply one-off resizing or scheduling.
Centralized FinOps-led analysis
A FinOps team starts generating reports and recommendations across accounts or subscriptions, often using provider-native or FinOps tooling.
Standardized governance and processes
Right-sizing is built into change management, design reviews, and operational runbooks.
Automated, policy-driven optimization
Actions (e.g., downsize, terminate, schedule off) are executed automatically within clearly defined guardrails.
This paper aims to help practitioners accelerate that journey while maintaining trust, safety, and reliability.
3. Personas and Collaboration
Right-sizing is not a purely technical exercise; it is a cross-functional practice.
3.1 Personas Involved
| Persona | Primary Responsibilities in Right-Sizing |
|---|---|
| FinOps Practitioner / Team | Run analyses, define policies, coordinate across teams, quantify savings/impact. |
| Engineering / Platform / SRE | Design and operate services, apply changes, validate performance and reliability. |
| Product / Service Owner | Accept trade-offs, prioritize optimization vs feature work, own business value. |
| Finance / FP&A | Integrate optimization into budgets and forecasts, validate financial outcomes. |
| Leadership (Tech & Business) | Sponsor the practice, set expectations, resolve conflicts, and align incentives. |
| Supporting Personas (ITAM, Security) | Ensure compliance, license alignment, and appropriate guardrails. |
3.2 Collaboration Patterns
Successful right-sizing practices share the following collaboration traits:
- Shared language:
Teams agree on what "right-sized" means per workload type (e.g., target utilization ranges, SLOs). - Transparent data:
Cost and performance data is shared broadly, with self-service access. - Joint decision-making:
Engineers, product owners, and FinOps jointly decide on significant changes to critical workloads. - Feedback loops:
Changes are reviewed post-implementation to confirm impact on cost and reliability, and lessons are shared.
4. Maturity Model for Right-Sizing
Right-sizing maturity can be expressed as Crawl / Walk / Run, aligned with FinOps maturity:
4.1 Maturity Overview
| Stage | Characteristics | Typical Behaviors & Activities |
|---|---|---|
| Crawl | Reactive, ad-hoc, limited visibility | Manual clean-ups, isolated efforts, limited reporting. |
| Walk | Structured, repeatable, cross-team awareness | Scheduled reviews, defined playbooks, partial automation. |
| Run | Integrated, policy-driven, automated | Continuous optimization, embedded in SDLC (Software Development Lifecycle) and operations. |
4.2 Detailed Maturity Characteristics
Crawl – Initial & Defined
Focus:
Basic visibility and low-risk savings.
Activities:
- Implementing cost and utilization dashboards per account/subscription.
- Tagging or grouping resources by owner, environment, or product.
- Manual identification and clean-up of:
- Idle instances
- Unattached storage volumes
- Zombie load balancers and IPs
Tooling:
Native cloud cost explorers, basic custom reporting, spreadsheets.
Walk – Rolled Out & Developed
Focus:
Establish right-sizing as a recurring practice.
Activities:
- Monthly or bi-weekly right-sizing review meetings for top spenders.
- Standard operating procedures (SOPs) for resizing, scheduling, and clean-ups.
- Integrating recommendations from:
- Cloud native recommendation tools
- Third-party optimization platforms
- Using right-sizing signals as input into commitment decisions (RIs, savings plans).
Tooling:
Enhanced dashboards, anomaly detection, and recommendation engines.
Run – Standardized & Sustained
Focus:
Automation, guardrails, and continuous improvement.
Activities:
- Policy-based automation for:
- Instance resizing and scheduling
- Storage lifecycle transitions
- Container and cluster auto-scaling
- Embedding right-sizing checks into:
- CI/CD pipelines
- Architectural review processes
- Platform APIs ("paved roads")
- Systematically tracking KPIs, SLOs, and incident impact.
Tooling:
FinOps platforms, infrastructure-as-code, event-driven automation, ML-powered analytics.
5. Foundational Practices
5.1 Data and Observability
A right-sizing practice depends on consistent, reliable data:
- Cost and usage at a minimally granular level (per resource or service).
- Utilization metrics relevant to each resource type (CPU, memory, disk, network, IOPS, requests).
- Performance and reliability metrics (latency, error rate, availability, saturation).
Best practice is to provide a single pane of glass where teams can see:

User story: for this "service/workload", in this "environment", here is its utilization, performance, and cost over time.
5.2 Automation and Decision Support
Manual right-sizing does not scale. Automation should be introduced in stages:
Automated Data Collection
Centralized ingestion of metrics from cloud providers, APM tools, and log systems.
Recommendation Engines
Rule-based or ML-based engines that suggest:
- Down/upsizing
- Alternative instance types
- Storage tier transitions
- Schedule optimizations
Policy-Driven Execution
Declarative policies that define:
- Conditions under which actions are automatically taken.
- Constraints (e.g., only for non-prod, only certain tags, limits on percentage change).
Feedback and Learning
Capture the impact of changes and feed that back into rules, models, and governance.
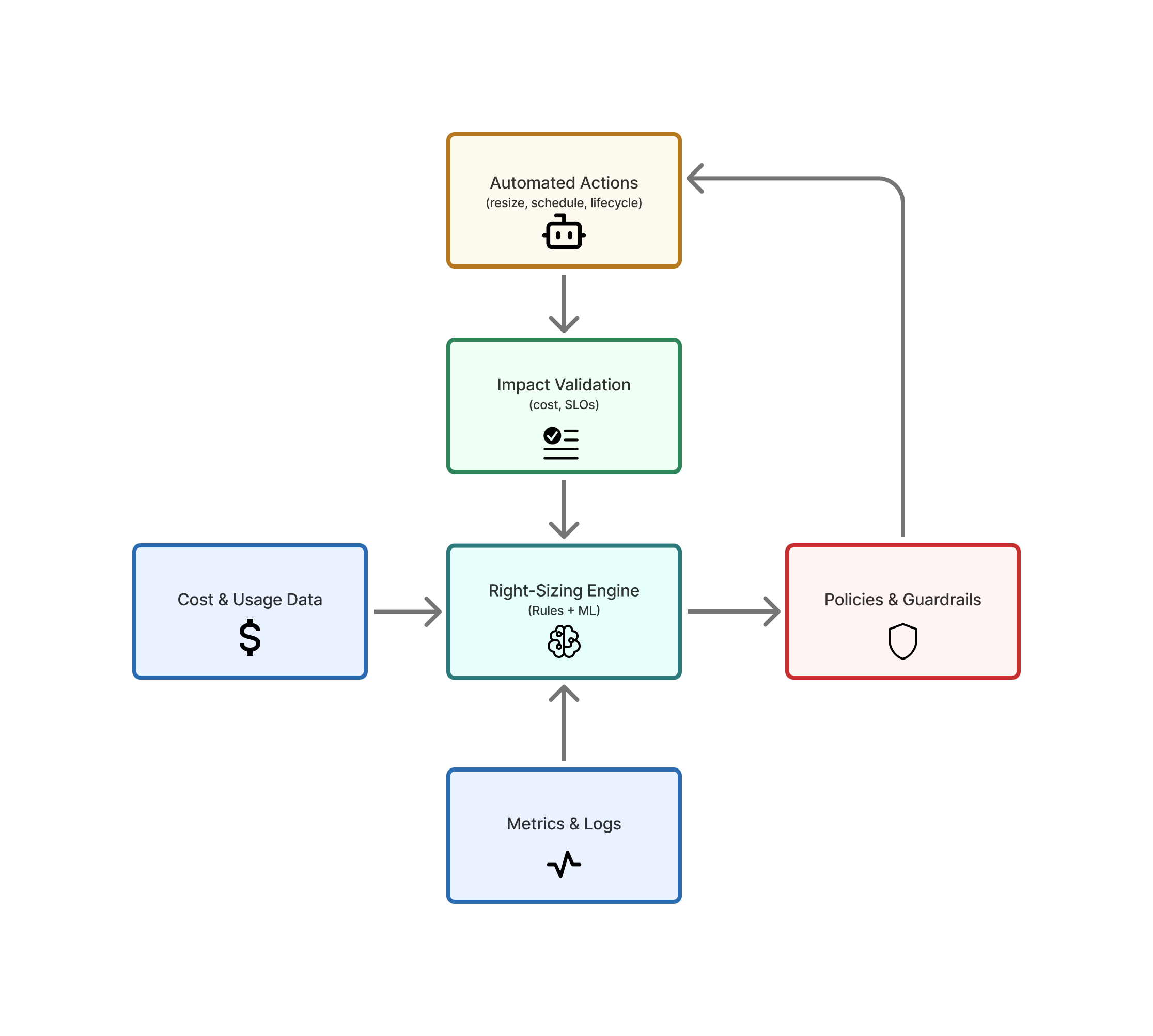
5.3 Balancing Cost, Reliability, and Performance
Right-sizing is not purely about cutting cost. Sustainable practices:
- Start from business outcomes and SLOs, not cost targets alone.
- Use workload profiles to understand:
- Baseline load
- Burst characteristics
- Seasonality
- Incorporate testing and validation:
- Load tests, stress tests, chaos experiments.
- Design for graceful degradation and elasticity:
- Allow services to scale or degrade predictably instead of failing abruptly.
- Maintain rollback mechanisms:
- Easy reversals of changes if the impact is negative.
6. Right-Sizing Opportunities by Layer
This section highlights common right-sizing levers across five layers. It is not exhaustive, but it focuses on high-impact opportunities that frequently appear in FinOps work.
6.1 Compute Resources (VMs, Managed Compute, Serverless)
6.1.1 Key Levers
| Focus Area | What to Look For | Typical Actions |
|---|---|---|
| Instance size vs utilization | CPU/Memory < 20–30% over long periods | Downsize to smaller instance, split workload, or consolidate. |
| Instance family alignment | Mismatch between workload profile & instance family | Move to compute, memory, or general-purpose family as needed. |
| Over-provisioned non-production | Idle or low-use dev/test/stage environments | Implement schedules, suspend or terminate unused resources. |
| Underused autoscaling groups | Groups always at max size or rarely scaling down | Adjust scaling policies, cooldowns, and metrics. |
| Low-density workloads | Many small instances with low utilization | Consolidate workloads onto fewer instances. |
| Over-reliance on on-demand | Stable, predictable workloads fully on-demand | Combine with RIs/savings plans; right-size then commit. |
| Misused burstable instances | Burstable instances constantly at or above baseline | Move to non-burstable types; adjust workloads or architecture. |
| "Always-on" utility services | Jump boxes, bastion hosts, build agents running 24/7 | Schedule or replace with on-demand / serverless alternatives. |
6.1.2 Practical Considerations
- Right-sizing compute often yields fast, visible savings, but can also introduce risk if:
- Performance patterns are not well understood.
- SLOs are not clearly defined and monitored.
- Start with non-production and low-risk workloads to build confidence and refine processes.
6.2 Storage Resources (Block, Object, File)
6.2.1 Key Levers
| Focus Area | What to Look For | Typical Actions |
|---|---|---|
| Tiering & lifecycle policies | Large data volumes rarely accessed | Apply lifecycle rules; move cold data to cheaper tiers. |
| Volume over-provisioning | Volumes significantly larger than used capacity | Resize volumes where supported or migrate to appropriately sized. |
| Unused or orphaned storage | Volumes not attached, old snapshots, stale buckets | Identify and delete after validation. |
| Redundant or duplicated data | Multiple copies of similar datasets | Deduplicate, compress, or consolidate datasets. |
| Overkill performance settings | High IOPS/throughput volumes with low I/O usage | Downgrade to cheaper storage tiers or lower performance configs. |
| Excessive snapshot/backup frequency | Very frequent snapshots with no clear retention policy | Rationalize retention, frequency, and retention tier. |
| Inefficient log and telemetry storage | Logs retained indefinitely in hot storage | Move to cold/archive tiers; shorten retention where appropriate. |
6.2.2 Practical Considerations
- Changes to storage may affect RPO (Recovery Point Objective) / RTO (Recovery Time Objective), legal retention requirements, or auditability.
- Involve security, compliance, and data owners when adjusting policies.
- Track storage costs by lifecycle stage (hot, cool, archive) to show benefits.
6.3 Database Services
6.3.1 Key Levers
| Focus Area | What to Look For | Typical Actions |
|---|---|---|
| Instance size & class | Sustained low CPU/Memory, I/O well below limits | Downsize DB instance; adjust storage throughput provisioned. |
| Replica counts | Many replicas with low read traffic | Reduce number of replicas; consider read scaling patterns. |
| Storage allocation & auto-scaling | Large allocated storage vs actual usage | Reduce allocated storage (where supported); tune autoscaling rules. |
| Backup & snapshot strategy | Excessive backup copies and long retention | Rationalize retention; move older backups to cheaper storage tiers. |
| Query & index inefficiencies | Constant performance complaints despite large DBs | Tune queries and indexes before scaling up hardware. |
| Caching and connection pooling | High DB load from repeated reads or poor connection use | Introduce caching layers; fix connection pooling configuration. |
6.3.2 Practical Considerations
- Right-sizing databases is high-stakes:
- Latency, error rates, and availability may be highly sensitive to capacity.
- Begin with read replicas, dev/stage databases, or non-critical workloads.
- Use changes as opportunities to pay down technical debt:
- Index cleanup
- Query optimization
- Partitioning and archiving strategies
6.4 Container / Kubernetes Workloads
6.4.1 Key Levers
| Focus Area | What to Look For | Typical Actions |
|---|---|---|
| Pod CPU requests/limits | Requests much higher than actual usage | Lower CPU requests; adjust limits with safe headroom. |
| Pod memory requests/limits | High requests with no OOM (Out Of Memory) events and low usage | Reduce memory requests; tune GC (Garbage Collection), caching, and app memory settings. |
| Node types and sizes | High fragmentation or low node utilization | Consolidate to fewer node sizes; choose node types that fit workloads. |
| Cluster auto-scaling configuration | Clusters rarely scaling down or stuck at high capacity | Adjust scale-up/down policies, timeouts, and metrics. |
| Namespace quotas and limits | No quotas; "noisy neighbor" issues | Implement quotas; align to team/workload budgets and expectations. |
| Image and resource garbage collection | Large numbers of unused images, pods, or PVCs (Persistent Volume Claims) | Implement regular cleanup jobs and policies. |
| Use of spot/preemptible nodes | Suitable workloads running only on on-demand nodes | Move batch/CI/stateless workloads to spot/preemptible nodes. |
| Logging verbosity | Excessive log volume consuming CPU, storage, network | Reduce log level; route certain logs to cheaper destinations. |
6.4.2 Practical Considerations
- Containers often hide over-provisioning:
- Pods look small, but aggregate resource requests per node or cluster may be high.
- Make cluster-level utilization visible to teams:
- Map cost and metrics back to namespaces, deployments, and services.
6.5 Network and Connectivity
6.5.1 Key Levers
| Focus Area | What to Look For | Typical Actions |
|---|---|---|
| Load balancer and gateway count | Many small or idle load balancers | Consolidate; remove unused; right-size throughput tiers. |
| Data transfer patterns | High cross-zone / cross-region traffic | Re-architect to minimize cross-boundary traffic where feasible. |
| Idle or oversized VPN/direct connect | Low utilization on expensive dedicated connections | Downgrade, consolidate, or schedule connections based on demand. |
| NAT gateways and public IPs | Many NAT gateways/public IPs with low or no usage | Consolidate NATs; remove unused public IPs; consider private access. |
| CDN and caching usage | Backends serving all traffic; low cache hit ratio | Introduce or tune CDNs; adjust cache policies. |
| Network appliances | Firewall, IDS/IPS, WAF appliances with low throughput | Right-size appliance tiers; autoscale where possible. |
| DNS and routing configurations | Complex, redundant routing setups | Simplify DNS and routing; tune TTL and caching. |
6.5.2 Practical Considerations
- Network costs can be harder to attribute; invest in clear cost allocation.
- Work closely with security and networking teams (often separate from application teams).
7. Operating Model and Governance
7.1 Core Processes
A sustainable right-sizing practice typically includes these recurring activities:
Discovery & Analysis
- Identify top N accounts/products by spend.
- Analyze utilization and performance for their key workloads.
- Generate a prioritized list of right-sizing candidates.
Review & Decision
- Conduct regular right-sizing review sessions with Engineering, Product owners, and FinOps.
- Decide which changes to implement, defer, or reject.
Implementation & Validation
- Apply changes via Infrastructure-as-code, Orchestration tools, or Cloud consoles (ideally only for emergencies or exceptions).
- Validate Performance, Reliability, and Cost impact.
Reporting & Feedback
- Report savings and impact to Teams and Leadership.
- Capture lessons learned and feed back into policies and automation.
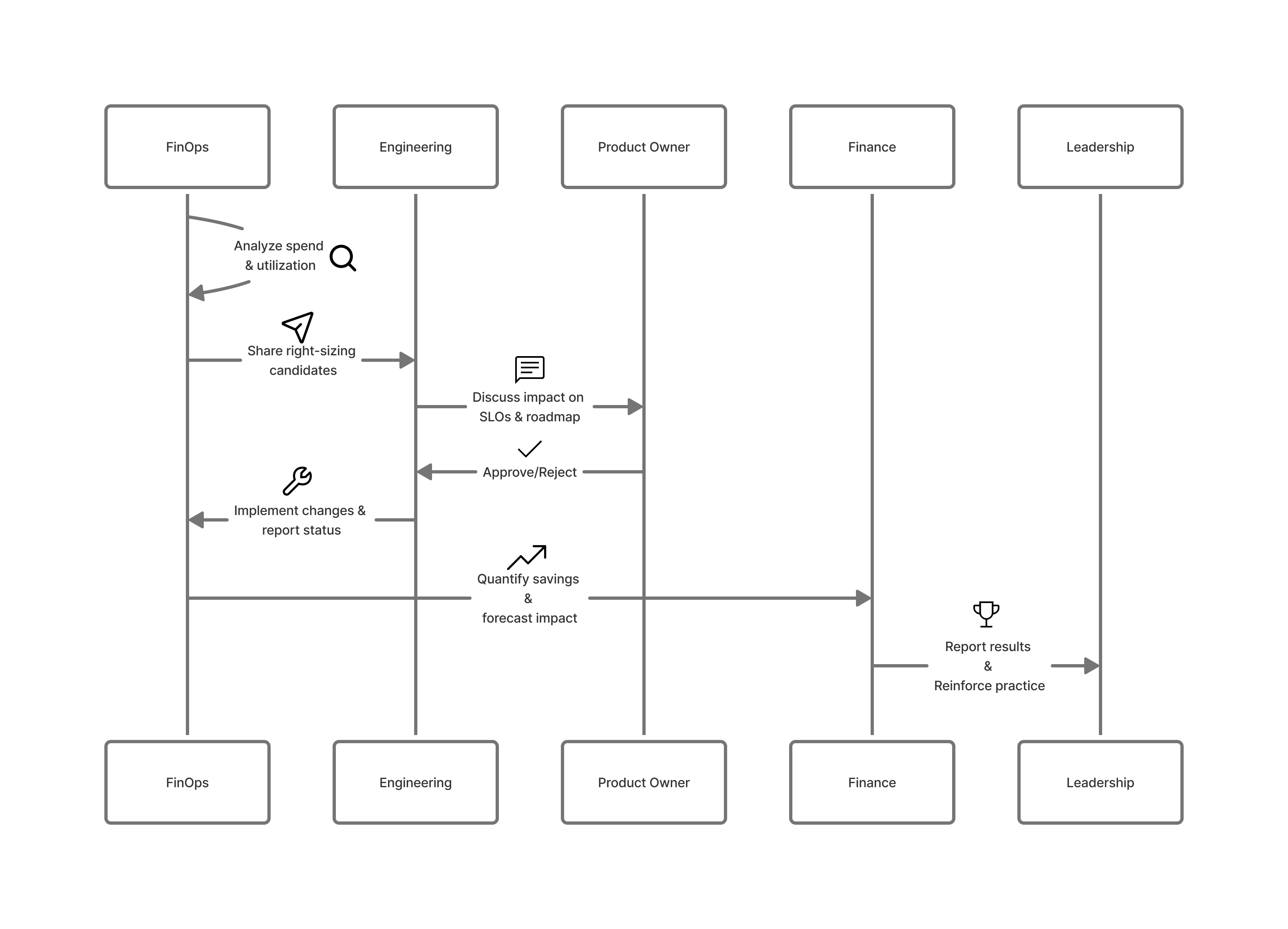
7.2 Governance and Guardrails
Key governance mechanisms:
- Policies that define:
- Which environments can be automatically right-sized.
- Minimum notice or review process for production changes.
- Required performance validation steps.
- Exception handling:
- Documented process for workloads that must deviate from standard policies (e.g., due to regulatory or business constraints).
- Alignment with other frameworks:
- ITIL / ITSM change management
- SRE practices (error budgets, SLOs)
- Security and compliance controls
8. Indicators of Success (KPIs)
A right-sizing practice should be measured and improved over time. Example KPIs:
8.1 Utilization and Waste
| KPI | Description | Example Target |
|---|---|---|
| % of compute spend right-sized or reviewed | Portion of compute spend under active governance | > 70% of compute spend in 12 months |
| Average CPU utilization of key workloads | CPU utilization in primary hours for right-sized services | 40–70% for steady workloads |
| % of storage in appropriate tiers | Hot vs cool vs archive mix aligned with access patterns | > 60% of rarely accessed data in cheap tiers |
8.2 Financial Outcomes
| KPI | Description | Example Target |
|---|---|---|
| Monthly savings from right-sizing | Gross or net savings per month from changes | 5–15% of addressable spend |
| Savings as % of total cloud spend | Contribution of right-sizing to overall FinOps outcomes | 3–10% of total cloud spend over a year |
| Avoided cost through right-sizing | Estimated cost avoided vs "no optimization" baseline | Increase year over year |
8.3 Process & Adoption
| KPI | Description | Example Target |
|---|---|---|
| Regularity of right-sizing review sessions | Frequency of sessions per key domain/product | Monthly or bi-weekly |
| % of changes implemented via automation | Portion of changes executed automatically | > 50% for non-prod, > 25% for prod |
| Average lead time from recommendation to change | Time from identification to production implementation | < 4 weeks for prioritized actions |
8.4 Reliability & Risk
| KPI | Description | Example Target |
|---|---|---|
| Incidents caused by right-sizing | Number of incidents where right-sizing contributed | Zero or near-zero |
| SLO compliance before vs after change | Comparative SLO adherence for right-sized workloads | No degradation |
9. Exceptions and Considerations
Not all workloads should be aggressively right-sized. Consider the following exceptions:
- Highly variable or unpredictable workloads
Where traffic patterns or data volumes are inherently unpredictable and hard to forecast. - Mission-critical, latency-sensitive services
Where the cost of an incident vastly outweighs possible savings. - Regulatory or contractual obligations
Where over-provisioning is explicitly required (e.g., for certain regulated industries). - Third-party or legacy systems
Where limited observability or control prevents safe changes.
In these cases, right-sizing might focus more on:
- Observability improvements first.
- Architectural changes to enable elasticity.
- Non-critical tiers (dev/test, staging, analytics) before touching production.
10. Recommended Practices & Implementation Checklist
The following checklist can be used as a practical starting point.
10.1 Quick Wins (First 3–6 Months)
- Identify top 5–10 products or accounts by cloud spend.
- Implement basic cost and utilization dashboards for these areas.
- Clean up obvious waste:
- Idle instances
- Unattached storage
- Zombie load balancers, IPs, NAT gateways
- Introduce schedules for dev/test environments.
- Hold your first right-sizing review session with engineering and product.
10.2 Building the Practice
- Document right-sizing guidelines:
- Target utilization ranges per workload type.
- Standard instance/storage types to prefer.
- Define roles and responsibilities per persona.
- Introduce structured recommendation pipelines:
- Right-sizing candidate reports.
- Review workflows.
- Start tracking right-sizing KPIs and savings.
10.3 Moving Toward Automation
- Implement policy-based automation for:
- Dev/test shutdown schedules.
- Non-critical instance downsizing.
- Storage lifecycle transitions.
- Integrate right-sizing checks into:
- CI/CD pipelines
- Design / architecture reviews
- Establish guardrails and exception processes.
- Regularly communicate wins (both savings and reliability outcomes) to maintain support.
11. Future Directions
As cloud and FinOps practices evolve, right-sizing will continue to intersect with:
- AI-driven optimization
More sophisticated ML models recommending configurations, patterns, and architectural changes. - Sustainability and ESG reporting
Using right-sizing outcomes to show CO₂ and energy reductions alongside cost savings. - Advanced workload management
Integrated views of:- Cost
- Performance
- Reliability
- Sustainability
This paper is intended as a foundation upon which further playbooks, case studies, and domain-specific papers can build—for example, right-sizing for AI/ML training clusters, data platforms, or SaaS multi-tenant architectures.
12. Related FinOps Capabilities and Resources
Right-sizing connects directly to several FinOps capabilities, including:
- Resource Utilization & Efficiency
The primary capability covered in this paper. - Workload Management & Automation
Embedding right-sizing into orchestration, CI/CD, and platform tooling. - Data Analysis & Showback
Providing transparent cost and utilization data to teams. - Managing Commitment-based Discounts
Using right-sized baselines to inform commitment decisions. - Forecasting
Incorporating right-sized baselines into forward-looking cost models.
Future work can explore detailed playbooks and case studies that build on this paper, focusing on specific providers, industries, or workload patterns.
References
FinOps Foundation. (n.d.). FinOps Framework Overview (updated 2025 with Scopes addition). https://www.finops.org/framework
(Core operating model, including Phases, Personas, Capabilities such as Resource Utilization & Efficiency, Workload Management & Automation, and Cloud Sustainability.)
FinOps Foundation. (2025). State of FinOps 2025. https://data.finops.org/library
(Annual survey insights on FinOps maturity, adoption, waste trends, and emerging practices like AI and sustainability.)
FinOps Paper Metadata (Internal Use Only)
| Key | Value |
|---|---|
| Size of Organization | Any |
| Size of Cloud Use | Any |
| Organizational Complexity | Any |
| Cloud Use Complexity | Any |
| Maturity of Cloud Adoption | Any |
| Maturity of FinOps practice | Any |
| FinOps team model | Any |
| Industry | Any |
| Capability | Resource Utilization & Efficiency, Workload Management & Automation, Cost Allocation |
| Persona Involved | Engineering, Finance, Product, Leadership |
| Cloud Used | Any |
| Level of Technical Detail | Medium |
| FinOps Tooling Used | N/A |