Tiered Services
Introduction
Exivity offers Service Providers the possibility to apply tiered prices and volume based rating to their services. Service Providers can benefit from the potentiality to set the price in a manner inversely proportional to the volume: the more you buy, the less you pay for that service. This way they can appeal to a wider base of customers and they can create their own sales strategy by offering them lower or higher entry-point prices.
Consider a scenario whereby customers pay per gigabyte of disk storage. For a non-tiered service, this is quite straightforward; we create the service (monthly or daily), configure a unit rate and the resulting charge will be the number of gigabytes consumed multiplied by the unit rate.
This is a somewhat restrictive model however and it may be preferable to automatically apply a series of discounts that kick in as the number of gigabytes consumed increases. In such cases, a tiered service provides just such capability.
There are a few key points about Tiering that are worth remembering:
- There are two models of tiering available in Exivity: Standard Tiering and Inherited Tiering.
- Tiering is always applied at the Service level.
- Tiering is always applied based on monthly consumption figures (even for non-monthly services).
- The tiered rating mechanism can be configured in the rate management screen.
Instance vs. Service quantities
In order to get the most from this documentation it is important to understand the difference between Service-level quantities and Instance-level quantities.
Usage data is comprised solely of instance-level quantities. Every record in the usage from Amazon AWS, Microsoft Azure or even a less account-orientated source such as VMware or Veeam backup will almost certainly contain a reference to a unique instance ID of some kind whether it be a hostname, host ID, resource ID, disk ID or similar.
Consider a hypothetical cloud vendor who offers three sizes of VM; small, medium and large all of which are charged on a monthly basis. Each has differing amounts of disk, CPU and RAM capacity but all usage records for VMs reference one of those three sizes.
A customer of that vendor could provision a number of VMs for different purposes. Perhaps a couple of small VMs for sandbox/test servers, half a dozen medium VMs for development servers and four large VMs; two for email servers and two for database servers.
With 2 small VMs, 6 medium VMs and 4 large VMs in service, the customer would expect to pay for them on that basis - 2 x small, 6 x medium and 4 x large - on the premise that this is how many VMs they are operating.
From the cloud vendor's perspective, there are still only 3 services, however, these being the small, medium and large VMs. It is the monthly charge for each VM size multiplied by the instances of those VMs that determine the final bill that the customer has to pay.
Exivity fully understands the difference between instances and services. In our above example, there would be three services but the billing records may look more like this:
| Service | Instance | Rate |
|---|---|---|
| Small VM | sandbox1 | 10.00 |
| Small VM | sandbox2 | 10.00 |
| Medium VM | dev_server1 | 15.00 |
| Medium VM | dev_server2 | 15.00 |
| Medium VM | dev_server3 | 15.00 |
| Medium VM | dev_server4 | 15.00 |
| Medium VM | dev_server5 | 15.00 |
| Medium VM | dev_server6 | 15.00 |
| Large VM | email1 | 20.00 |
| Large VM | email2 | 20.00 |
| Large VM | database1 | 20.00 |
| Large VM | database2 | 20.00 |
It can be seen that regardless of the number of services offered there can be any number of instances. Services are defined in a finite service catalogue but there is no hard limit on the number of instances that can be instantiated (well, short of trying to spin more of them up than the cloud can support but that's a little academic in practice).
Reports provided by Exivity are powered by a charge engine that processes usage data and emits charge records. Each charge record can represent either a service-level or an instance-level summary of cost.
In the above scenario, a greatly simplified view of the charge records produced by Exivity would be as follows:
| Type | Service | Instance | Quantity | Charge |
|---|---|---|---|---|
| Service | Small VM | - | 2 | 20.00 |
| Instance | Small VM | sandbox1 | 1 | 10.00 |
| Instance | Small VM | sandbox2 | 1 | 10.00 |
| Service | Medium VM | - | 6 | 90.00 |
| Instance | Medium VM | dev_server1 | 1 | 15.00 |
| Instance | Medium VM | dev_server2 | 1 | 15.00 |
| instance | Medium VM | dev_server3 | 1 | 15.00 |
| Instance | Medium VM | dev_server4 | 1 | 15.00 |
| Instance | Medium VM | dev_server5 | 1 | 15.00 |
| Instance | Medium VM | dev_server6 | 1 | 15.00 |
| Service | Large VM | - | 4 | 80.00 |
| Instance | Large VM | email1 | 1 | 20.00 |
| Instance | Large VM | email2 | 1 | 20.00 |
| Instance | Large VM | database1 | 1 | 20.00 |
| Instance | Large VM | database2 | 1 | 20.00 |
Note that the service-level records are aggregations of the instance level records, both in terms of quantity and charge. The aggregation renders the 'instance' column meaningless for service-level records but should drill-down be required then the instance-level records are available for closer examination.
Drill-down is important as it provides the ability to look inside the aggregated service-level charges in order to see the individual instances that contributed to those charges.
Instance-level records represent the most granular view of the data possible.
This concludes our brief diversion into the difference between Service-level and Instance-level charge records but bear in mind that tiering in Exivity is always applied at the Service level.
Exivity also provides drill-downs for tiered services and details of how the instance-level records accurately sum to the service-level records (not only in quantity but also in charge and on a per-bucket basis) are covered in subsequent sections of this documentation.
Standard vs. Inherited Tiering
Developing further the scenario previously outlined in the Introduction section, let us consider the following desired business model for pricing storage per gigabyte:
| Bucket | Quantity range | Rate |
|---|---|---|
| 1 | 0 + | 1.00 |
| 2 | > 100 | 0.80 |
| 3 | > 1000 | 0.60 |
Exivity uses the term Bucket to distinguish between each of the quantity ranges. Buckets are always numbered, starting from 1, and the first bucket will always have a quantity range of 0+
The first 100 gigabytes consumed are to be charged at 1.00 unit of currency each. For any quantity over 100, up to 1000 (inclusive), they are to be charged at 0.80 each and for any quantity over 1000 they are to be charged at 0.60 each.
Exivity supports two different methods of applying this business rule each of which will result in a differing final charge. These methods are Standard and Inherited tiering.
Standard Tiering
Standard Tiered pricing works so that the price per unit changes once each quantity within a "tier" has been reached.
If 2000 gigabytes of storage was consumed then the resulting allocation to each bucket, and the final charge, would be as follows:
| Bucket | Quantity | Rate | Bucket charge |
|---|---|---|---|
| 1 | 100 | 1 | 100.00 |
| 2 | 900 | 0.8 | 720.00 |
| 3 | 1000 | 0.6 | 600.00 |
The final charge after applying Standard Tiering as shown in the table above would be the sum of the bucket charges, thus 100 + 720 + 600 = 1,420.00 .
The rate tier interval is always monthly, meaning the tiered rates will be applied after calculating the monthly quantity totals for a service.
Inherited Tiering
The Inherited Tiering mechanism is designed to optimize service costs by automatically moving data to the most cost-effective tier.
This model places the entire quantity consumed into a single bucket, which is the highest-numbered bucket that would have any quantity allocated to it if Standard Tiering was applied.
To illustrate this, we can continue with the case above: if the 3rd (and highest) bucket had some quantity allocated to it and Inherited Tiering was applied, then the result would be as follows:
| Bucket | Quantity | Rate | Bucket charge |
|---|---|---|---|
| 1 | 0 | 1 | 0.00 |
| 2 | 0 | 0.8 | 0.00 |
| 3 | 2000 | 0.6 | 1200.00 |
In other words as each bucket is filled, its contents are carried over to (inherited by) the next bucket. The final charge after applying Inherited Tiering is simply the charge associated with the bucket into which all the quantity was allocated, thus 1,200.00 in the example above.
How to configure tiered pricing
Minimum commit in combination in Tiering is currently not supported.
First, you need to set a service to be Tiered.
-
Navigate to the Services > Overview menu and select a service from the list on the right side of the screen.
-
Click the Unlock button to enable edit mode.
-
Scroll down to the Billing section and select the preferred Tiering: Standard or Inherited.
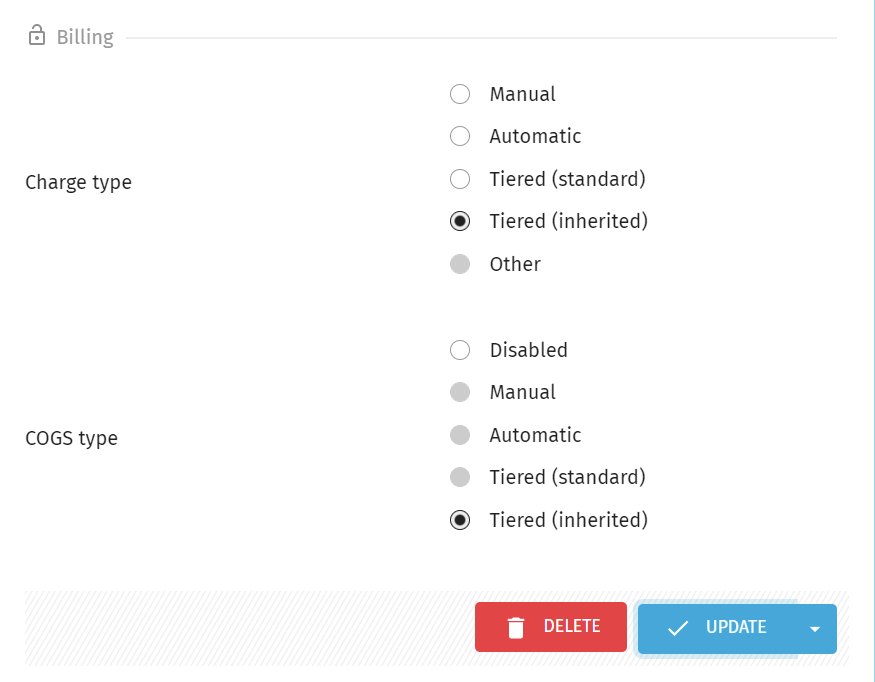
- Click Update to apply your changes.
Next, you need to create your tiered model which will apply to the service you just updated.
-
Navigate to the Services > Rates menu and select the service from the list on the right side of the screen.
-
Click on the +New button at the top next to Revisions or the one at bottom of the Revision box.
-
Choose the start date in the Effective date field.
-
Choose the preferred Aggregation level. Consult the documentation for Aggregation Levels and Account Hierarchy to get a better understanding.
-
Then you may add your preferred intervals_/_buckets for the selected service, by clicking on the green + button. For example:
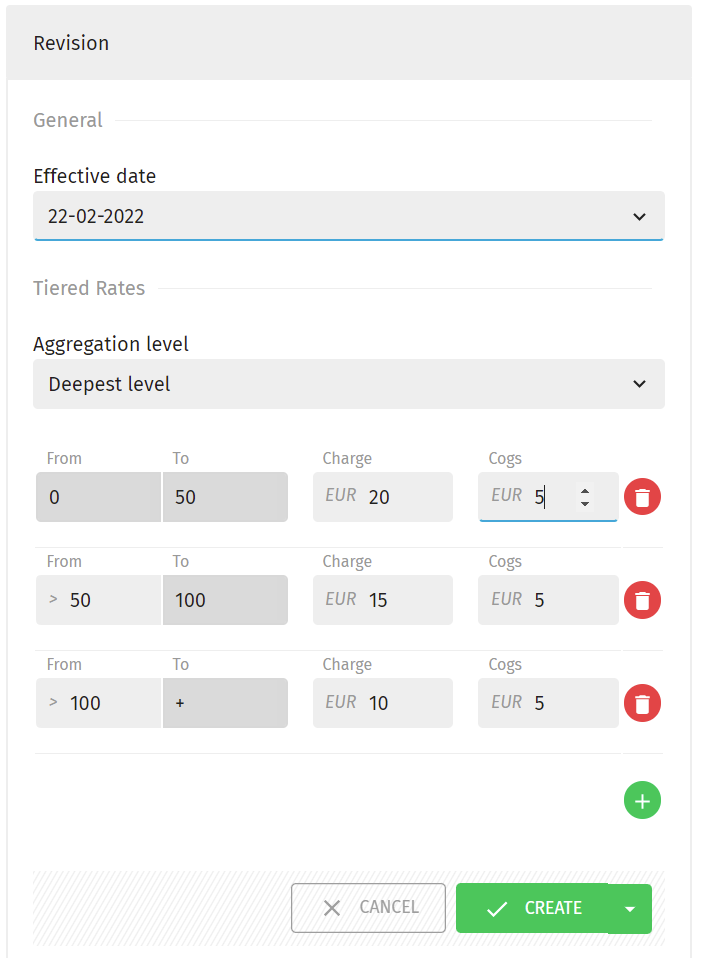
- Finally, click Create to save your changes.