Amazon AWS CUR (Athena)
This Tutorial is for the AWS CUR Athena Extractor if you want to use the standard AWS CUR Extractor please use this tutorial.
Prerequisites
This tutorial assumes that you have CUR (Cost and Usage Report) set up in your AWS environment. If this is not the case please follow the steps in Turning on the AWS Cost and Usage Report before proceeding.
Please note that in order to deploy this solution the S3 bucket to which CUR reports are written must reside in one of the following AWS regions:
- Northern Virginia
- Ohio
- Oregon
- Mumbai
- Seoul
- Singapore
- Sydney
- Tokyo
- Frankfurt
- Ireland
- London
At this point in time, only the previous regions have all the necessary services deployed.
Introduction
This tutorial shows how to build a serverless solution for querying the AWS CUR Report using Exivity. This solution makes use of AWS serverless services such as Lambda and Athena, as well as other commonly used services such as S3, CloudFormation, and API Gateway. The following topics will be covered:
- Solution Overview
- Launching the CloudFormation Template
- Creating the Lambda function and API Gateway
- Configuring an Extractor
- Configuring a Transformer
- Creating your Report
Solution Overview
The Billing and Cost Management service writes your AWS Cost and Usage report to the S3 bucket that you designated when setting up the service. These files can be written on either an hourly or daily basis.
The CloudFormation template that accompanies this tutorial builds a Serverless environment containing a Lambda function that reads a CUR file, processes it and writes the resulting report to an output S3 bucket. The output data object has a prefix structure of "year = current-year " and "month= current-month ". For example, if a file is written 13/09/2018 then the Lambda function outputs an object called "bucket-name/year=2018/month=09/file_name".
The next step in the template is to translate this processed report into Athena so that it can be queried. The following diagram shows the steps involved in the process:
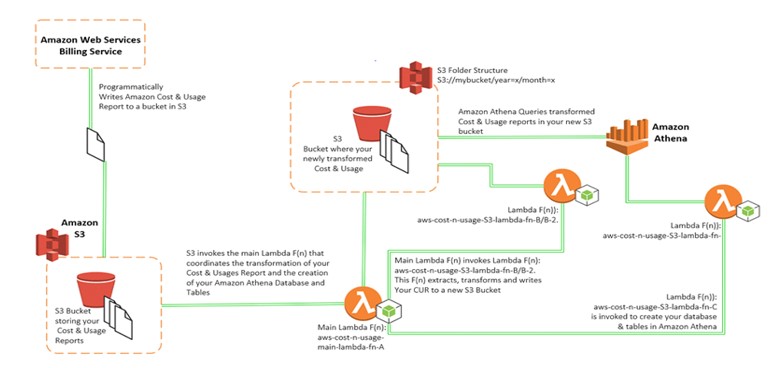
Afterwards, we will create a Lambda function to query the Athena database, returning a URL with the results of the query in CSV format. We will also create an API EndPoint with the AWS API Gateway service, which is used by Exivity to retrieve the data.
Launching the CloudFormation template
To deploy this solution successfully the following information is required:
- The name of your AWS Cost and Usage report.
- The name of the S3 bucket in which the reports are currently stored.
Firstly, launch the CloudFormation template that builds all the serverless components that facilitate running queries against your billing data. When doing this, ensure that you choose the same AWS Region within which your CUR S3 bucket is located.
Click on ![]() in the region associated with the S3 bucket containing your CUR files (this tutorial uses Ireland (eu-west-1) for illustrative purposes, but all the supported regions work in the same way).
in the region associated with the S3 bucket containing your CUR files (this tutorial uses Ireland (eu-west-1) for illustrative purposes, but all the supported regions work in the same way).
Now follow the instructions in the CloudFormation wizard, using the following options, and then choose Create.
- For CostnUsageReport, type the name of your AWS Cost and Usage report.
- For S3BucketName, type a unique name to be given to a new S3 bucket which will contain the processed reports.
- For s3CURBucket, type the name of the bucket into which your current reports are written.
While your stack is building, a page similar to the following is displayed.
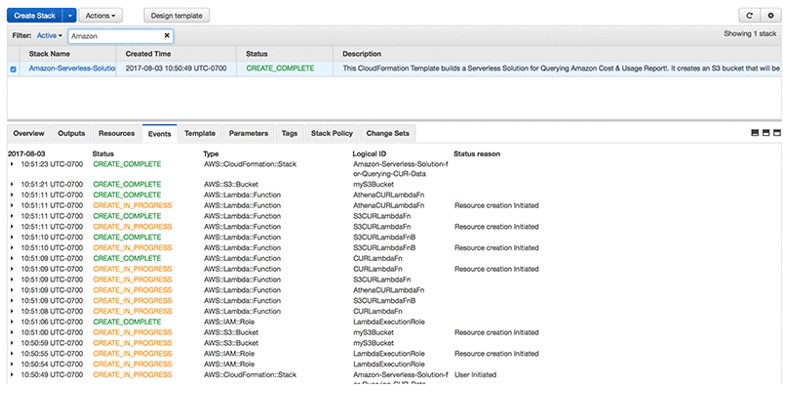
When the Status column shows CREATE_COMPLETE, you have successfully created four new Lambda functions and an S3 bucket into which your transformed bills will be stored.
Once you have successfully built your CloudFormation stack, you can create a Lambda trigger that points to the new S3 bucket. This means that every time a new file is added to, or and existing file is modified in, the S3 bucket the action will trigger the lambda function.
Create this trigger using the following steps:
- Open the Lambda console.
- Choose Functions, and select the aws-cost-n-usage-main-lambda-fn-A Lambda function (note: do not click the check box beside it).
- There should be no existing triggers. Choose Trigger, Add trigger.
- For Trigger type (the box with dotted lines), choose S3.
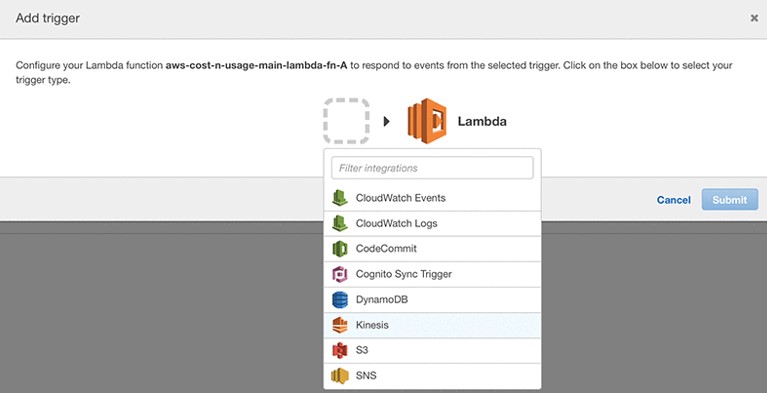
- Select the S3 bucket withing which your CUR reports are stored.
- For Event type, choose Object Created (All) and check Enable trigger.
- Click Submit.
The database and table are not created until your function runs for the first time. Once this has been done, Athena will contain the database and table.
Athena stores query results in S3 automatically. Each query that you run has a results file in CSV format and a metadata file (*.csv.metadata) that includes header information such as column type, etc.
Testing (Optional)
Once you have successfully added the trigger to the S3 bucket in which the Billing and Cost Management services writes your CUR reports, test the configuration using the following steps.
- In the S3 path to which AWS writes your AWS Cost and Usage Billing reports, open the folder with your billing reports, open the folder with your billing reports. There will be either a set of folders or a single folder with a date range naming format.
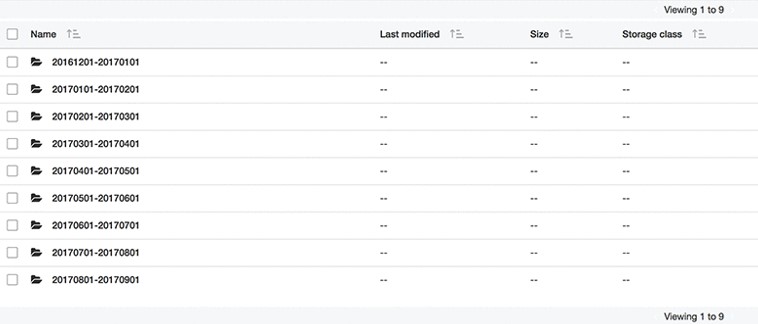
- Open the folder with the data range for the current month. In this folder, there is a metadata file that can be found at the bottom of the folder. It has a JSON extension and holds the S3 key for the latest report.
- Download the metadata file. Ensure that the name of the file on your machine is the same as the version stored on your S3 bucket.
- Upload the metadata file to the same S3 path from which you downloaded it. This triggers the Lambda function aws-cost-n-usage-main-lmbda-fn-A.
- In the S3 bucket that you created to hold your processed files, choose the "year=" folder and then the "month=" folder that corresponds to the current month. You should see the transformed file there, with the time stamp that indicated that it was just written.
Creating the Lambda function and API Gateway
To automate this process a CloudFormation template will be provided. This template will create an IAM role and Policy so that our API can invoke Lambda functions. Then it will create a Lambda function with the capabilities of querying our previously created Athena Serverless DB, and save the output in an S3 bucket in .csv format, (this output will be later retrieved by Exivity). Finally, it will deploy an API Gateway allowing us to create an endpoint for our Lambda function, this is the endpoint that the Exivity extractor will consume. Make sure to launch the CloudFormation template in the same region that you have deployed the previous one.
Let's start by downloading the CloudFormation template (you only need to choose one of the formats, both are supported by AWS):
Then follow the next steps:
- Go to the CloudFormation console.
- Choose Create Stack.
- Choose Upload a template to Amazon S3.
- Select from your computer the template that you have downloaded.
- Follow the CloudFormation wizard - Add a Name to the Stack and select I acknowledge that AWS CloudFormation might create IAM resources with custom names in the last step.
- Once the stack is created you should see an CREATE_COMPLETE message.

- Click on Output to take a note of your endpoint (you will need to input this in the Exivity extractor).

Next, we will associate an API Gateway trigger to our Lambda function:
- Go to the Lambda console.
- Choose the QueryAthena2 function.
- Under Add Triggers select API gateway. You should see an image like the following:
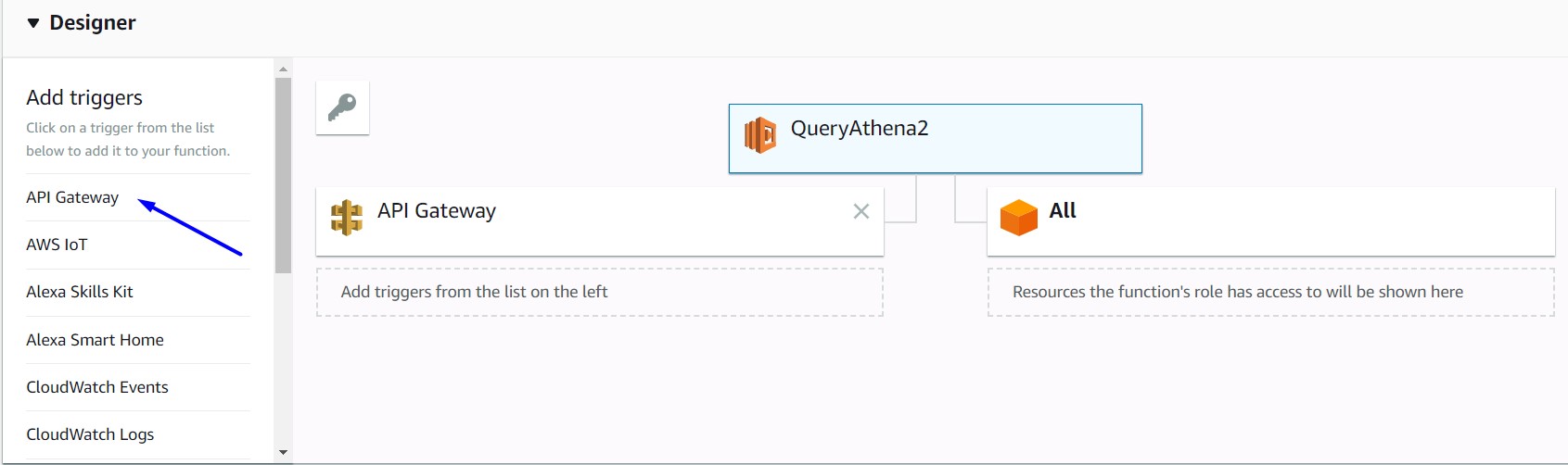
- Click on API Gateway figure to configure it.
- On API select QueryAthena2.
- On Deployment Stage select v1.
- On Security select Open.
- Choose Add.
- Choose Save.
You should see a screen like this:

Finally, we will deploy the API Gateway:
- Go to the API Gateway console.
- Choose QueryAthena2.
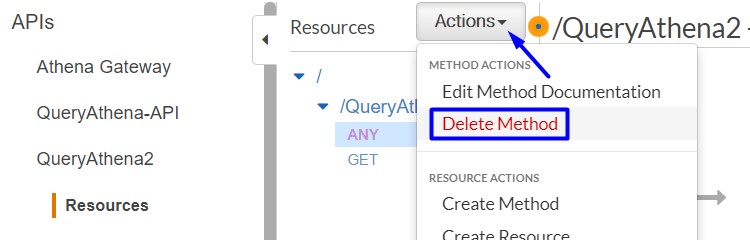
- In the Resources section, click on the ANY method.
- In Actions, choose Delete Method.
- Click on Delete.
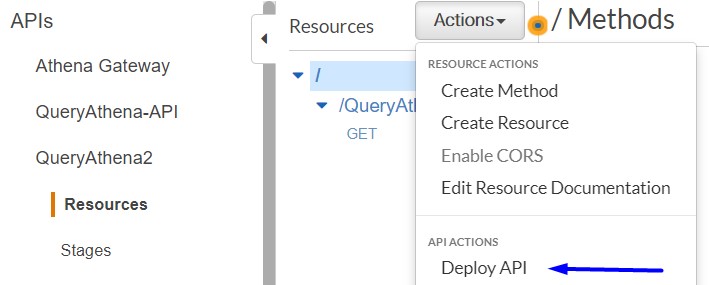
- In the Resources section, choose Actions.
- Click on Deploy API
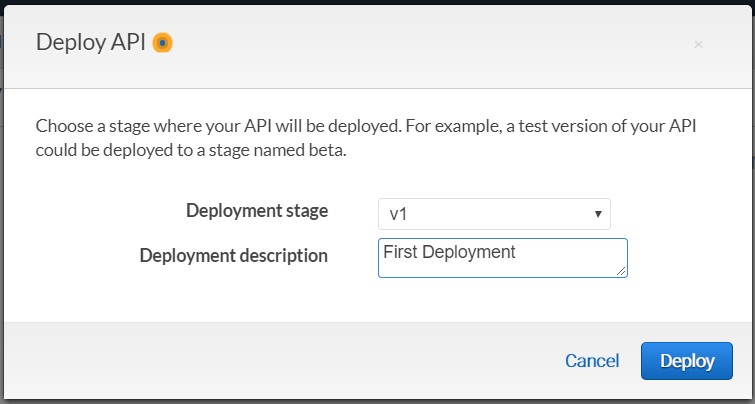
- In Deployment Stage select V1.
- Add a Deployment Description.
- Choose Deploy.
Securing the API Gateway
Initially, the created API endpoint is public and as such is vulnerable to the possibility of misuse or denial-of-service attacks. To prevent this, associate an API Key with the endpoint as per the following steps:
- Inside the API Gateway dashboard, select the QueryAthena2 API
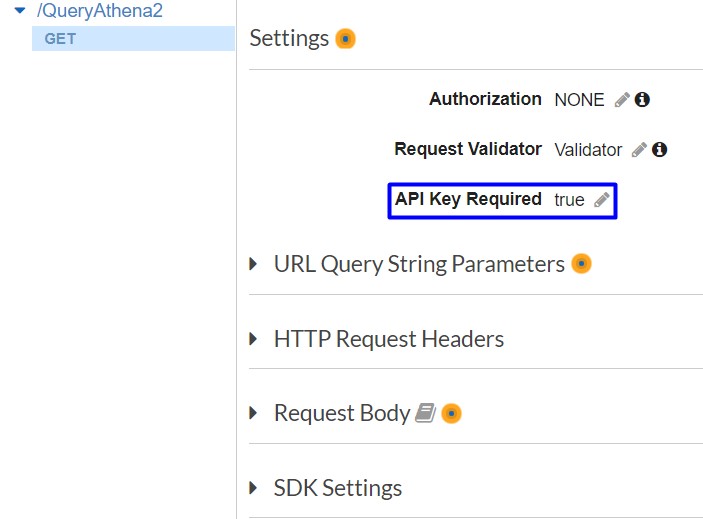
- In Resources, select Method Request
- In Settings, change API Key Required to True
- Click on Actions and choose Deploy API to effect the change
- In Deployment Stage, select v1 and click on Deploy
- Go to the API Keys section

- Click on Actions and select Create API Key
- In Name write ExivityAPIKey
- Click on Save
- Copy the API Key, as this will be required by the Exivity configuration
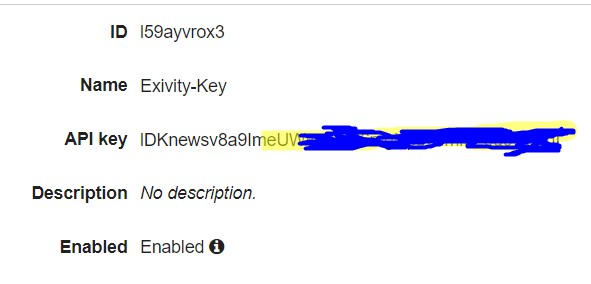
- Go to Usage Plan
- Click on Create.
- In Name write ExivityUsagePlan
- In the Throttling Section, change Rate to 100 and Burst to 10
- In the Quota Section, change it to 50000 requests per Month
- Click on Next
- Click on Add API Stage
- In API, select QueryAthena2 and in Stage select v1

- Confirm the changes and click on Next
- Click on Add API Key to Usage Plan
- Select ExivityAPIKey, confirm the changes
- Click on Done
The API Key is now required to access the API endpoint thus adding a layer of security to mitigate unauthorized access attempts.
Configure Extractor
To create the Extractor in Exivity, browse to Data Sources > Extractors and click the Create Extractor button. This will try to connect to the Exivity Github account to obtain a list of available templates. For AWS, please click AWS_CUR_Extractor from the list. Provide a name for the Extractor in the name field, and click the Create button.
Once you have created the Extractor, go to first tab: Variables
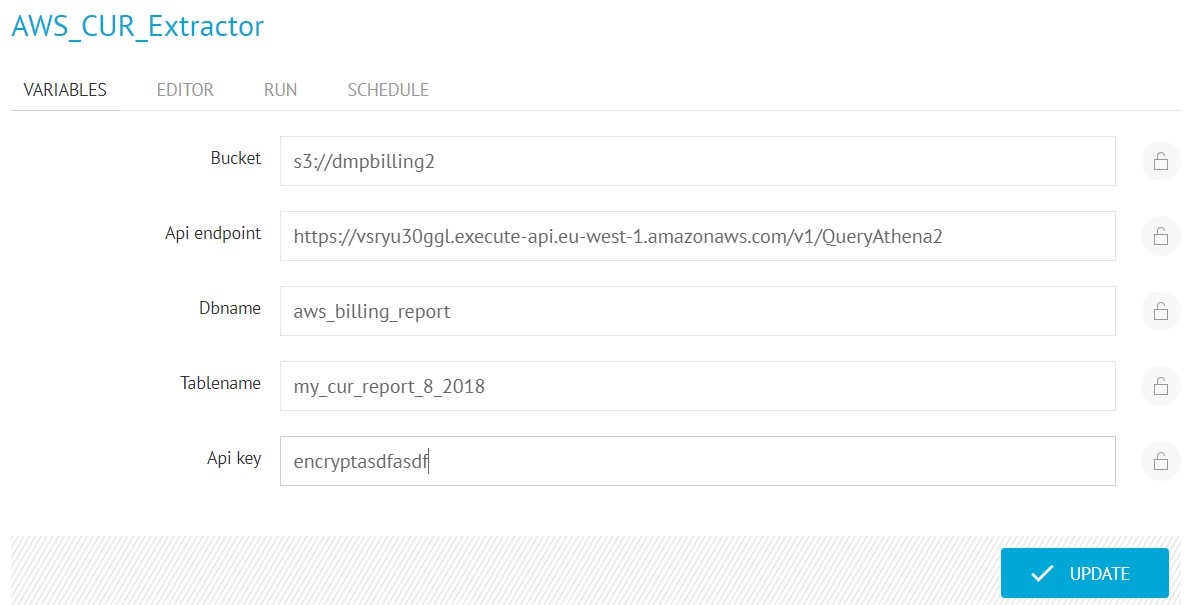
- In the Bucket variable specify the name of the S3 bucket where the .csv with the output of the query will be saved (The S3BucketName previously specified when launching the CloudFormation template).
- In the Api endpoint variable specify the API endpoint previously created plus the route /QueryAthena.
- In the DBname variable specify the name of your DB, you can find it in the Athena main Dashboard.
- In the Tablename variable specify the name of the table inside your DB, you can find it in the Athena main Dashboard.
- In the API_Key variable specify the API Key that we have created in the Securing API Gateway Section.
Once you have filled in all details, go to the Run tab to execute the Extractor for a single day:
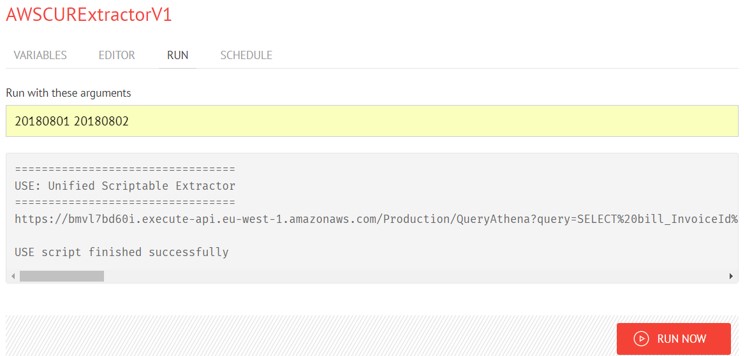
The Extractor requires two parameters in yyyMMdd format:
- from_date is the date for which you wish to collect consumption data.
- to_date should be the date immediately following from_date.
These should be specified as shown in the screenshot above, separated with a space.
When you click the Run Now button, you should get a successful result.
Configure Transformer
Once you have successfully run your AWS CUR Extractor, you should be able to create a Transformer template via Data Sources > Transformers and click the Create Transformer button. Select the AWS CUR Transformer and run it for a single day as a test. Make sure that it is the same day as for which you extracted consumption data in the previous step.
Create Report
Once you have run both your Extractor and Transformer successfully create a Report Definition via the menu option Report Definition via the menu Reports > Definitions:
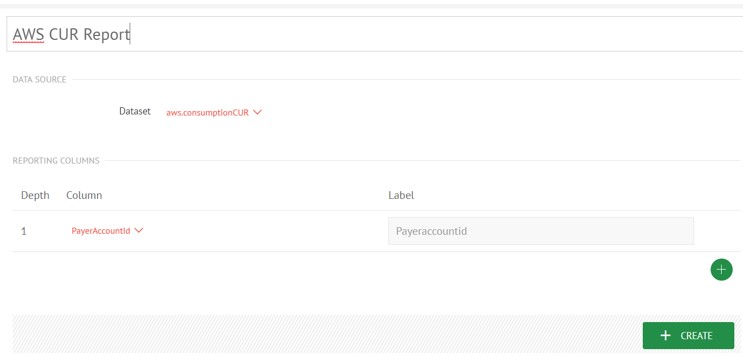
Select the column(s) by which you would like to break down the costs. Once you have created the report, you should then click the Prepare Report button after first making sure you have selected a valid date selector shown when preparing the report.

Once this is done you should be able to run any of Accounts, Instances, Services or Invoices report types located under the Report menu for the date range you prepared the report for.